
采集文章流程:列表页 → 获取内容页网址 → 内容页字段分析
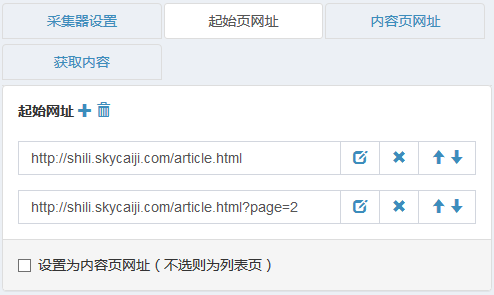
起始页网址
以http://shili.skycaiji.com/article.html为例,所有文章都在该列表中,即起始页为该网址
可添加多个起始页(例如列表分页)
内容页网址
点击“保存”后我们在“内容页网址”中测试抓取内容页网址

默认抓取所有网址(包括样式和js文件)
有些网址不包含域名(因为程序是直接抓取html源码的),可以在“采集器设置”中选中“自动补全网址”
我们只需要采集文章页面,通过分析文章网址的格式大致为“article/news/show/id/数字.html”
直接在“结果网址过滤>>必须包含”中输入“article/news/show/id/”,保存测试看看

如需精准还可以输入正则“article/news/show/id/d+.html”(d+是匹配数字)
想过滤某些网址在“不能包含”中输入,例如过滤掉25、27、29的文章,输入:“25|27|29”即可
如果列表页布局比较复杂有很多个文章列表区域,而我们仅需要获取某个区域的文章,使用“从选定区域中提取网址”,新手推荐“xpath”获取形式,可在“获取内容>>测试>>测试抓取数据>>分析网页”中输入列表页网址,点击页面元素即可获取相应的xpath值
如果内容页链接不能直接获取(通过js生成)或者需要拼接成新网址,可以在“匹配内容网址”中设置
获取内容
分析出内容页网址后,我们需要抓取文章的标题、正文等信息则要添加字段来匹配出数据
新手推荐使用“xpath”匹配,在“测试>>分析网页”中输入一个文章链接
分析页面中点击获取到标题xpath:“//*[@id="title"]/h1[1]”,正文xpath:“//*[@id="content"]”
分别添加字段:标题、正文,获取方式选择“xpath匹配”,将获取到的xpath值填入即可


保存后点击测试抓取数据,效果:

正文中包含很多html标签,如需过滤可使用“数据处理>>html标签过滤”功能
如需采集分页内容,请参考文章分页教程
- 1163K网站系统登录滑动验证-阿里人机验证配置教程
- 2SEO站长每天需要做的9件事
- 3蓝天采集器关于DZ帖子发布的修改参考,技术有限仅供参考。
- 4pbootcms类型站点怎么查看图片、网页元素的路径和大小和颜色
- 5蓝天采集器为什么无法安装
- 6蓝天采集器反馈个BUG
- 7蓝天采集器自动采集不定时停止运行
- 8蓝天采集器系统单次采集过多数据会卡死
- 9蓝天采集器求Xiuno BBS发布接口
- 10蓝天采集器采集的页面 每天页数都会变怎么办 ?
- 11蓝天采集器内容页上一级是分页
- 12pbootcms火车头采集器免登录发布使用教程
- 13蓝天采集器请问一下,能采集JS渲染的内容吗?
- 14蓝天采集器如何关联多页采集规则教程
- 15163K网站系统七牛云加速域名开启https教程
- 16蓝天采集器能不能在或者内容页的时候也能用XPATH
- 17蓝天采集器正在校验更新文件
- 18蓝天采集器采集器取消了自动补全网址,还是会自动补全
- 19蓝天采集器发布到本地数据库失败
- 20网站的外链资源圈如何来建立
-

影视站建设教程-零基础搭建影视站
影视建站 1.购买域名/主机 2.绑定解析 3.安装程序 4.安装影视模板 5.采集教程 常见问题 零基···
-
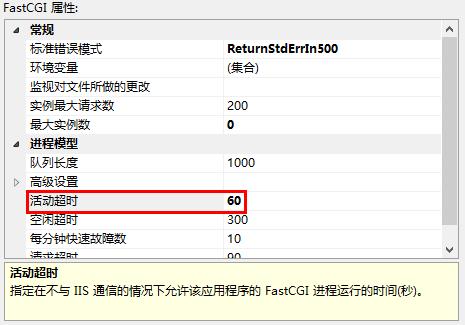
蓝天采集器采集中断、自动采集无效、图···
因为web服务器有运行时间限制,所以只要采集执行时间太长都会导致程序中断,需要修改web服务器的超时时间IIS服务器:桌面>计算机>右键>管理>服务和应用程序>IIS>根目录>FastCGI 设置&···
-

蓝天采集器这种情况怎么解决呀
1688产品详情页 里的内容详情也是封装的。而且每条内容页详情的URL都不一样。这种情况怎么得到他们的数据? 添加 内容页网址》关联页网址获取 ,匹配出内容详情的网址 字段 数据源 选内容详情
-

蓝天采集器发布时绑定cms插件的时候···
当我们的采集规则写好了以后,最重要的一步就是绑定发布插件入库到我们数据库里面;蓝天采集器默认插件并不是很多,不是每一个发布插件都能识别出来,这时候呢就需要我们手动去选择数据绑定如下图所示。这里的路径是我们蓝天采集器发布插件的路径;记得后缀一···
-

蓝天采集器奇葩了模拟匹配可以获取内容···
这是因为啥

 扫一扫微信咨询
扫一扫微信咨询