
新手完全按照手册来的,自己尝试用后台的中国农业网新闻做测试,把原来的规则匹配改为chrome提取的xpath却一直抓不到数据,反倒是用chrome或xpathhelper插件匹配都是可以的,是规则写的不对么?
比如抓标题"https://www.zgny.com/news/nongyeyaowen/201805/60978.html",写xpath规则为"/html/body/div[@class='qhbg']/div[@class='m'][2]/div[@class='hnw_xwzx_left']/div[@class='chy_contents_c1']/h1" 在chrome中调试就有数据,在系统测试就抓不到标题
测试了下可以抓取到xpath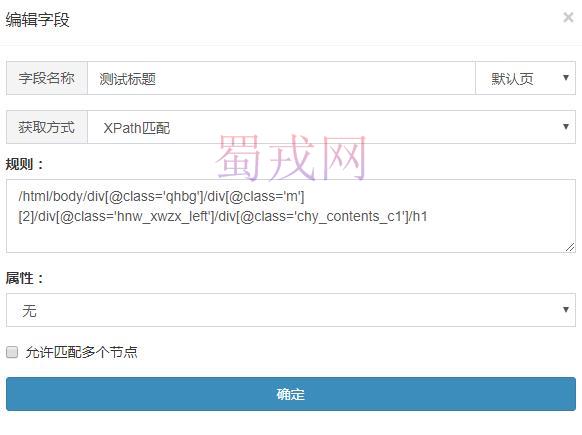

你的运行环境发下
admin 发表于 2018-5-12 21:54
测试了下可以抓取到xpath
操作系统 Linux 3.10.0-514.26.2.el7.x86_64
运行环境 Apache
数据库 mysql 5.5.57-log
PHP版本 5.6.34
上传限制 50M
我试了下属性选无可以采集到
 之前用的chrome测通的innerText就抓不到,必须选无么
innerText是你自定义的属性吧?属性选“无”或者“text”效果一样
相关知识点:
标题
测试
运行环境
之前用的chrome测通的innerText就抓不到,必须选无么
innerText是你自定义的属性吧?属性选“无”或者“text”效果一样
相关知识点:
标题
测试
运行环境
- 1蓝天采集器采集小说示例教程
- 2手把手教你做PbootCMS自动替换图片地址为七牛云cdn镜像链接操作教程
- 3蓝天采集器拼接网址问题--卡壳了
- 4蓝天采集器您好,我的采集到这卡住了,好像是没法写数据库一样
- 5163K网站系统腾讯云验证码配置说明
- 6蓝天采集器如何采集disucz站的回帖评论信息
- 7蓝天采集器怎么取到图片的名字啊
- 8自带采集PHP小说网站源码:功能强大KYXSCMS狂雨小说cms网站源码
- 9蓝天采集器API接口使用问题
- 10163k地方门户系统升级时遇到的一些报错解决办法
- 11SEO学习向导流程适合SEO零基础入门站长
- 12proc_open函数如何开启操作教程
- 13易优cms(eyoucms)蓝天采集器发布插件
- 14蓝天采集器2.0版本后不能自动采集了
- 15蓝天采集器三级网页采集方式?
- 16给PbootCMS增加个换行格式化标签br=1
- 17PbootCMS中文域名获取授权码注意点
- 18蓝天采集器有没有可能增加这么一个“采集筛选”的功能?
- 19pbootcms系统网站必须要做的seo要点
- 20蓝天采集器hadsky采集
-

蓝天采集器1条已采集起始网址被过滤
但是测试好像没问题。,我哪里错了,求说明 设置》采集设置》每次采集间隔时间 admin 发表于 2018-6-1 21:41 设置》采集设置》每次采集间隔时间 感谢站长问题已经解决,是我之前采集过了才会被过滤
-

蓝天采集器能否针对图片进行,其他保存···
图片路径后期会优化 远程图片下载不来,设置下 采集设置》图片本地化》下载超时,你是外网图片下载慢就设置时间长些 最后需求估计不行,因为数据已经发布了,你只能在cms或数据库中修改 120秒应该够了 数据多 勾选 采集设置》实时发布数据 ···
-
蓝天采集器关于标题获取,部分标题带“···
本帖最后由 zmh886 于 2019-5-13 10:01 编辑 因为采集器获取标题会自动处理掉“-”后面的部分,对于部分网站可以使用获取description 来获取到“更完整的标题” 2019.05.02发现新问题 标题包含单引···
-
蓝天采集器使用常见问题及解决办法
采集中断、自动采集无效、图片下载不了详见:https://www.srso.cn/fy/657.htmlcli命令模式php可执行文件:默认自动识别,识别不了,在linux系统中关闭目录跨站保护,手动输入:可输入环境变量名“php”(需要系···
-

蓝天采集器XPath规则插件-火狐f···
火狐浏览器firebug和firepath插件安装方法(最新)。以下为具体步骤。第1步:下载火狐55以内版本安装包,安装时迅速设置禁止自动更新版本,取消勾选自动更新(目的是防止火狐浏览器自动升级)54版本火狐浏览器的下载地址:64位火狐54···

 扫一扫微信咨询
扫一扫微信咨询