
分类信息在网络中的使用率仅次于文章,通常为列表格式数据,所以采集分类信息的流程很简单,可以直接将列表页当做内容页来采集,如果需要从列表页中分析出内容页,那么采集流程就类似于文章采集,本教程重点讲解采集列表形式的数据
前面说了可以直接将列表页当做内容页来采集,那么起始页设置成什么呢?一般可以设为分类链接列表或者关键词搜索链接列表(该教程绕过这步)
以http://shili.skycaiji.com/info.html为例,基本上所有数据都在该列表中,所以无需进入内容页采集,直接将起始页设置为内容页网址
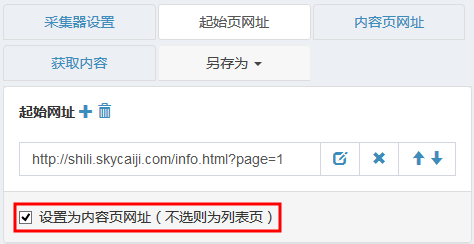
保存后点击测试抓取内容页网址,然后点“分析”进入分析网页界面
列表数据都有一定的格式规律,我们先匹配出每一条数据的包裹层,点击图片元素,然后使用底部控制台中的父元素来调出包裹层

得出第一条数据包裹层xpath://*[@id="list"]/li[1]
同类型包裹层xpath://*[@id="list"]/li
在“获取内容”中添加字段,获取方式选“xpath匹配”,规则输入同类型的xpath,勾选“允许匹配多个元素”并选中“循环入库”

保存测试下看

成功抓取到包裹层列表,接下来从每个包裹层中匹配出字段数据
以第一条数据为例,第一条包裹层html源码:
先添加一个图片字段,获取方式选“字段提取内容”,选中“包裹层”字段,提取内容选“xpath匹配”
由于是从包裹层中提取图片,所以图片xpath只需要相对于包裹层就可以了(不用根据整个页面写xpath)
填写图片xpath://img[@class='img'],属性选“src”

保存测试看看

成功从每个包裹层中匹配出了相应的图片链接
接下来再添加几个字段,操作类似于图片:
标题xpath://div[@class='title']
地址xpath://div[@class='address']
户型xpath://div[@class='huxing']
标签xpath://div[@class='tags']
均价xpath://div[@class='price']
注意以上字段xpath匹配的属性选择“text”可直接过滤掉html代码

测试结果:

采集列表数据的教程就是这些了,流程很简单,就是编写字段xpath比较繁琐,还有一种不使用包裹层而是直接将每个字段都设置为循环入库(xpath匹配使用同类型元素的xpath)
两种方式都已上传云平台
包裹层:http://www.skycaiji.com/Collect/rule/detail/id/100156
同类型:http://www.skycaiji.com/Collect/rule/detail/id/100111
如有细节方面问题请在本帖内回复!
- 1蓝天采集器wordpress发布到网站数据库需怎样设置入库规则?
- 2ZKEYS公有云业务管理系统蓝天采集器自动采集入库操作教程
- 3蓝天采集器采集URL地址中包含“&”的BUG
- 4163K网站系统好店商家如何扫码核销
- 5蓝天采集器pbootcms文章 (PbootDemoSkycaiji)插件如何设置调用整站目录
- 6访问宝塔控制面板出现无法访问此网站拒绝了我们的连接请求!处理方法
- 7蓝天采集器v1.2码云clone下来的,安装完成后菜单是英文
- 8蓝天采集器为啥我的不能自动采集,有没有和我遇到同样问题的?
- 9蓝天采集器想爬去的页面 需要点击开始后才能出结果 怎么爬取
- 10蓝天采集器dedecms发布问题
- 11pbootcms系统网站必须要做的seo要点
- 12蓝天采集器wrodpress本地调试出错怎么办
- 13蓝天采集器采集网址问题
- 14蓝天采集器能不能在或者内容页的时候也能用XPATH
- 15蓝天采集器系统内核会升级吗
- 16PbootCMS建站模板中常用的一些组合调用代码
- 17蓝天采集器资讯列表页链接采集规则教程分享
- 18蓝天采集器建议官方参照简数补充一些功能
- 19蓝天采集器请教数据采集覆盖或修改之前入库信息的设置
- 20迅睿CMS文章火车头采集器使用教程说明
-

蓝天采集器又有新的问题!版主来哈。关···
突然发现网易新闻采集页面编码是UTF-8而内容页面却是gb2312这个怎么解决啊。前面开启自动检测编码,页面无法检测出来,内容貌似也是一样,设置成UTF-8后 页面出连接了,而内容却乱码了 这个怎么解决啊。我吧采集规则传到云平台了,希望大家···
-
蓝天采集器PHP7的版本什么时候出
目前我们的服务器环境是PHP7的,想用蓝天采集器,用不了 临时解决:把文件上传到SkycaijiApp/Admin/Controller 覆盖可以访问后台
-

阿里云windows服务器买了单独的···
相信我们许多站长朋友们都会遇到一个问题就是就是在参加一些活动的时候,会购买一些活动服务器。活动服务器呢配置上面还可以,价格相对来说就是非常的优惠,但是这类服务器都是有一个弊端那就是云盘只有一个,有的是20G有的是40G,今天蜀戎网络就给大家···
-
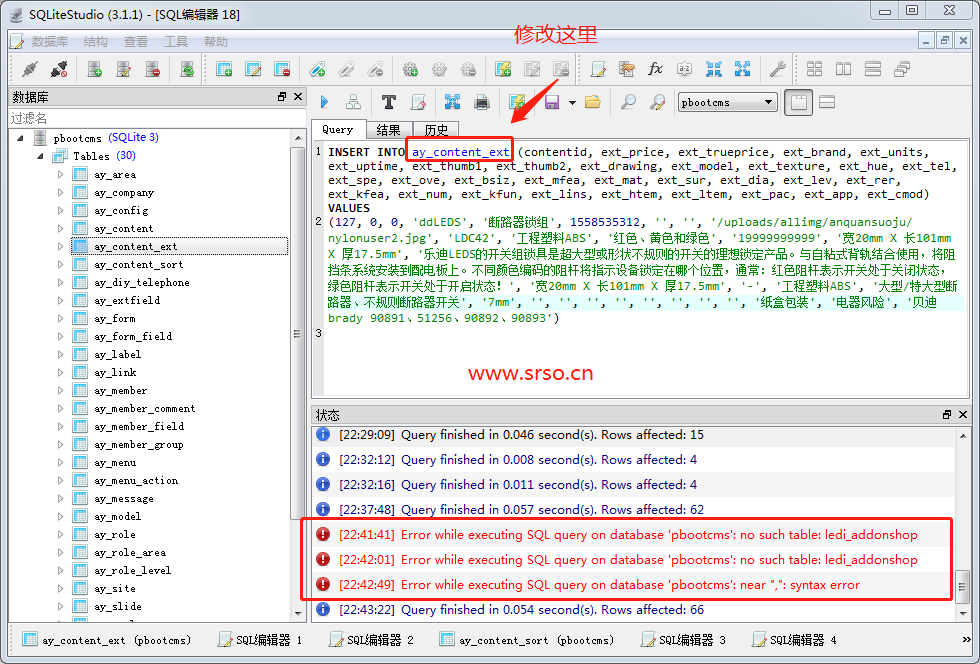
dedecms自定义标签导入pboo···
dedecms的自定义字段太多了,各种各样的;所出现的报错问题也是千奇百怪。今天蜀戎网络就给大家讲解一下,当出现:[22:14:48] Error while executing SQL query on database 'pbo···
-
pbootcms升级到3.0.3+最···
pbootcms系统在升级3.0.3最新版本以后伪静态会出现问题,二级目录正常,所有的文章点击后跳转首页,用的宝塔nginx的环境,php版本5.6等,各种环境都有,都会出现这个情况,比如我测试的阿里云虚拟主机和服务器。今天呢蜀戎给大家讲解···

 扫一扫微信咨询
扫一扫微信咨询