
小说采集流程:小说列表页→单本小说章节列表页→小说章节页
小说比文章多了一级网址,可以将单本小说章节列表页视为文章列表页,小说章节页视为文章内容页,多出来的是小说列表页即小说名称列表
那么小说列表页就是起始页,当然你也可以将单本小说章节列表作为起始页(类似于文章采集),本教程重点讲解多本小说采集
以http://shili.skycaiji.com/novel.html为例,将其设置为起始页网址
分析出单本小说章节列表网址规则为:
注意不能直接将规则填入到“内容页网址获取”中,因为“内容页网址获取”表示的是最后一级页面即小说的章节内容页
此处匹配出的网址是章节列表页,应该添加为“多级网址”再匹配出内容页网址
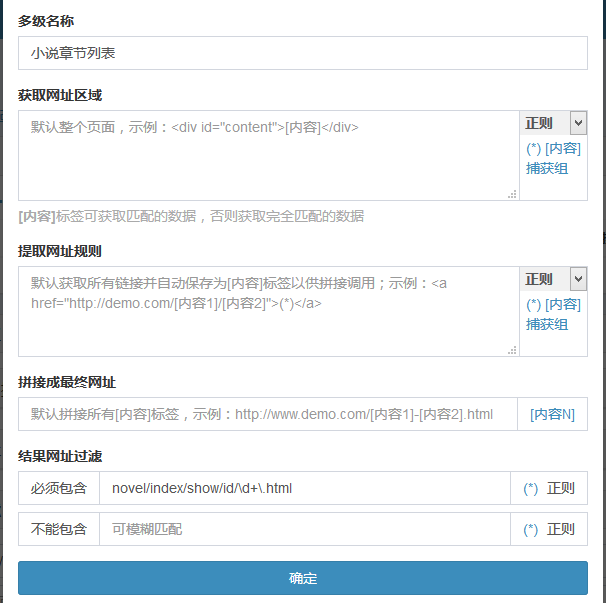

保存后测试抓取内容页网址

如图所示从起始页中抓取到了2本小说,每本小说抓取到了32条网址(此时抓取到的是全部链接,包含样式和js文件链接,需要过滤出章节网址)
进入http://shili.skycaiji.com/novel/index/show/id/1.html分析出章节网址规则:
这时就可以将规则填入“内容页网址获取》结果网址过滤》必须包含”中,保存后再测试:

成功抓取到所有章节链接
接下来就是抓取章节的标题、正文了,点击上图的分析,即可直接在页面中点击元素获取xpath值
获取到的标题xpath://*[@id="title"]/h1
正文xpath://*[@id="content"]
分别添加字段:标题、正文,获取方式选择“xpath匹配”,将获取到的xpath值填入即可


保存后测试抓取数据:

如果章节有分页,可以参考文章分页教程
- 1pbootcms分类栏目都调用一级栏目的banner图教程
- 2影视站建设教程-零基础搭建影视站
- 3163K网站系统相亲自动实名认证-百度AI配置教程
- 4163K系统S2版升级S3前注意事项和准备工作
- 5蓝天采集器关于标题获取,部分标题带“-”获取不完整的解决办法
- 6蓝天采集器Z-BlogPHP 1.5.1 Zero发布插件有谁成功的
- 7蓝天采集器反馈个BUG
- 8蓝天采集器请问怎么采集新浪的这段网址
- 9多语言建站看这里:PbootCMS多语言建站常见问题(如何搭建中英文站)
- 10163K网站系统相亲人脸识别验证-百度AI配置教程
- 11163K网站系统网站客服的QQ在线状态设置说明
- 12蓝天采集器我想在起始页设置参数,每执行一次加20怎么弄,跪求
- 13蓝天采集器如何将采集到的文章发布到米拓的新闻资讯里
- 14163K网站系统提现和结算出错需检查的项目
- 15Discuz门户蓝天采集器入库字段(发布插件)都有哪些
- 16pbootcms您访问路径含有非法字符,防注入系统提醒您请勿尝试非法操作!
- 17给PbootCMS增加个换行格式化标签br=1
- 18蓝天采集器获取纯文本问题
- 19蓝天采集器这种情况怎么解决呀
- 20蓝天采集器数据库问题
-

蓝天采集器采集URL地址中包含“&a···
/service/service.df?pageid=8509&backend_action_id=3021883&3770_id_no= 采集地址如上,如果地址中包含“&”符号,会采集到的地址内容解析不正确,采集不···
-

蓝天采集器如何循环采集某一个页面
如题 目标站的页面URL不变,内容会每都更新 网址会被记录排重,只能采一次,后期改进
-
蓝天采集器能不能在或者内容页的时候也···
感觉用xpath会方便很多 2.0版已加入
-

蓝天采集器无法安装怎么回事???
阿里云服务器,上传文件访问安装页面404,PHP版本5.4. 输入index.php试试 thankphp目录下thanphp.php文件 的83行增加一直 index vk : define('_PHP_FILE_', r···
-

蓝天采集器安装到最后一步出错了!怎么···
环境 win7 64位+php5.4.45+Apache 知道了 mysql密码输错了

 扫一扫微信咨询
扫一扫微信咨询